
Training an artificial intelligence agent to do something like navigate a complex 3D world is computationally expensive and time-consuming. In order to better create these potentially useful systems, Facebook engineers derived huge efficiency benefits from, essentially, leaving the slowest of the pack behind.
It’s part of the company’s new focus on “embodied AI,” meaning machine learning systems that interact intelligently with their surroundings. That could mean lots of things — responding to a voice command using conversational context, for instance, but also more subtle things like a robot knowing it has entered the wrong room of a house. Exactly why Facebook is so interested in that I’ll leave to your own speculation, but the fact is they’ve recruited and funded serious researchers to look into this and related domains of AI work.
To create such “embodied” systems, you need to train them using a reasonable facsimile of the real world. One can’t expect an AI that’s never seen an actual hallway to know what walls and doors are. And given how slow real robots actually move in real life you can’t expect them to learn their lessons here. That’s what led Facebook to create Habitat, a set of simulated real-world environments meant to be photorealistic enough that what an AI learns by navigating them could also be applied to the real world.
Such simulators, which are common in robotics and AI training, are also useful because, being simulators, you can run many instances of them at the same time — for simple ones, thousands simultaneously, each one with an agent in it attempting to solve a problem and eventually reporting back its findings to the central system that dispatched it.
Unfortunately, photorealistic 3D environments use a lot of computation compared to simpler virtual ones, meaning that researchers are limited to a handful of simultaneous instances, slowing learning to a comparative crawl.
The Facebook researchers, led by Dhruv Batra and Erik Wijmans, the former a professor and the latter a PhD student at Georgia Tech, found a way to speed up this process by an order of magnitude or more. And the result is an AI system that can navigate a 3D environment from a starting point to goal with a 99.9% success rate and few mistakes.
Simple navigation is foundational to a working “embodied AI” or robot, which is why the team chose to pursue it without adding any extra difficulties.
“It’s the first task. Forget the question answering, forget the context — can you just get from point A to point B? When the agent has a map this is easy, but with no map it’s an open problem,” said Batra. “Failing at navigation means whatever stack is built on top of it is going to come tumbling down.”
The problem, they found, was that the training systems were spending too much time waiting on slowpokes. Perhaps it’s unfair to call them that — these are AI agents that for whatever reason are simply unable to complete their task quickly.
“It’s not necessarily that they’re learning slowly,” explained Wijmans. “But if you’re simulating navigating a one-bedroom apartment, it’s much easier to do that than navigate a 10-bedroom mansion.”
The central system is designed to wait for all its dispatched agents to complete their virtual tasks and report back. If a single agent takes 10 times longer than the rest, that means there’s a huge amount of wasted time while the system sits around waiting so it can update its information and send out a new batch.
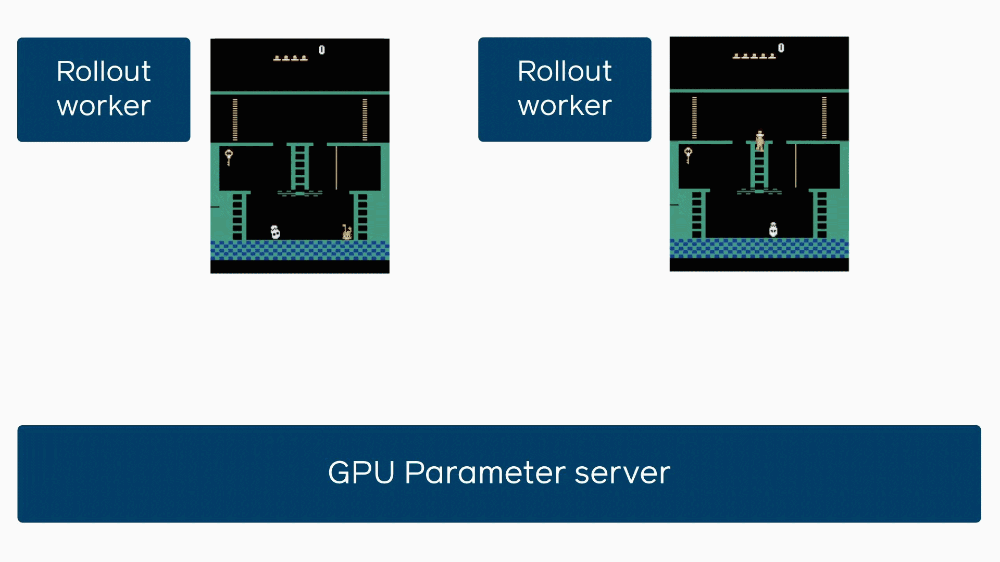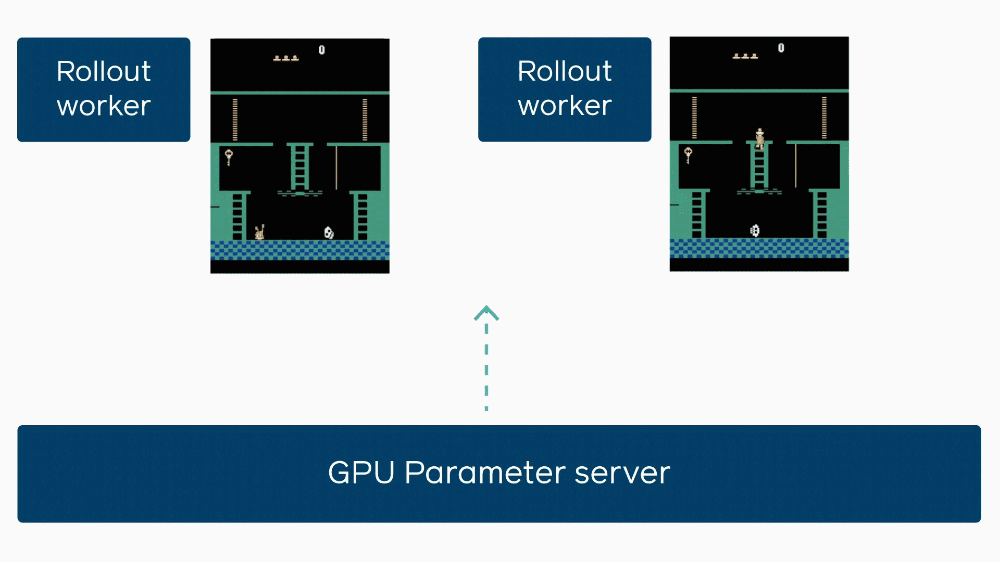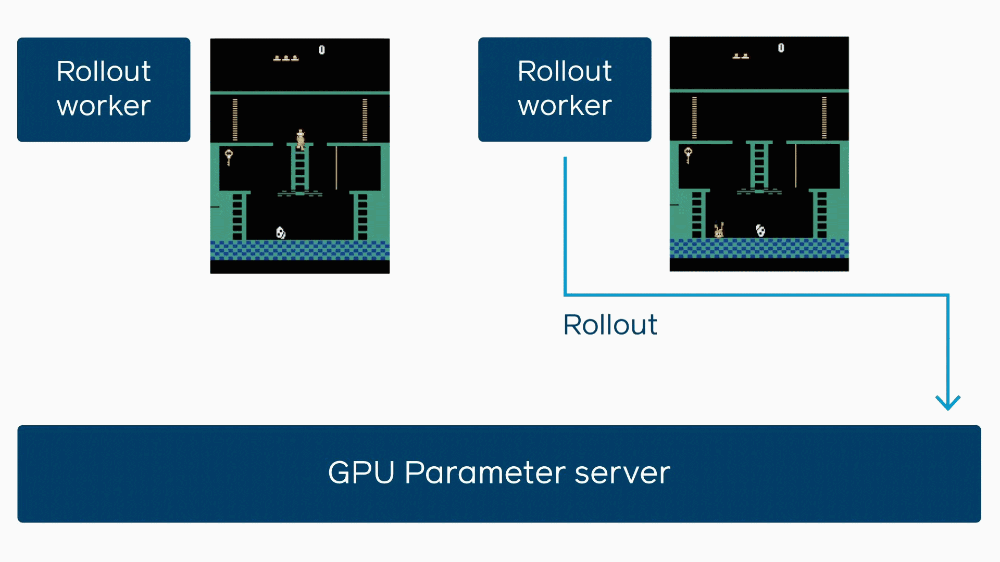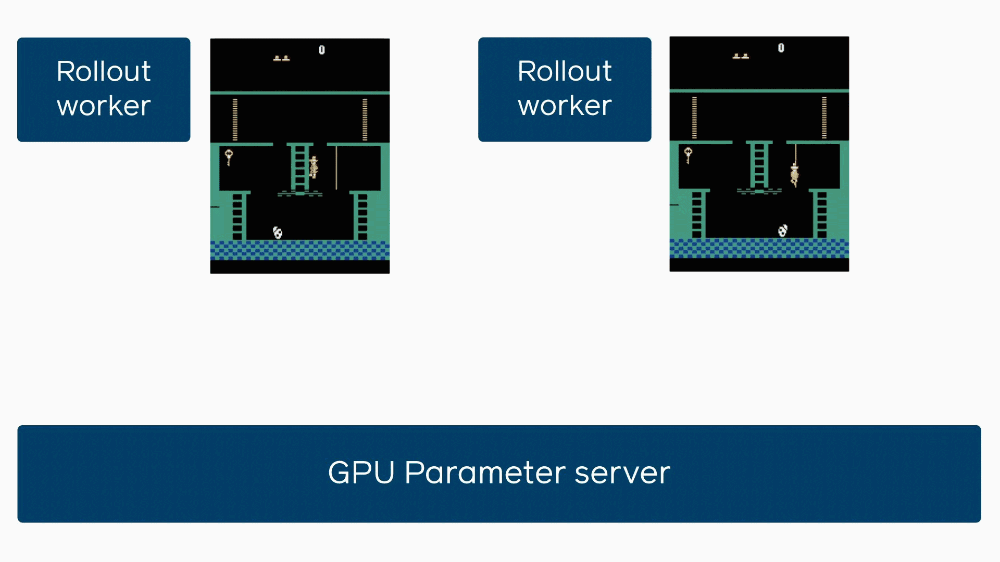
This little explanatory gif shows how when one agent gets stuck, it delays others learning from its experience.
The innovation of the Facebook team is to intelligently cut off these unfortunate laggards before they finish. After a certain amount of time in simulation, they’re done, and whatever data they’ve collected gets added to the hoard.
“You have all these workers running, and they’re all doing their thing, and they all talk to each other,” said Wijmans. “One will tell the others, ‘okay, I’m almost done,’ and they’ll all report in on their progress. Any ones that see they’re lagging behind the rest will reduce the amount of work that they do before the big synchronization that happens.”

In this case you can see that each worker stops at the same time and shares simultaneously.
If a machine learning agent could feel bad, I’m sure it would at this point, and indeed that agent does get “punished” by the system, in that it doesn’t get as much virtual “reinforcement” as the others. The anthropomorphic terms make this out to be more human than it is — essentially inefficient algorithms or ones placed in difficult circumstances get downgraded in importance. But their contributions are still valuable.
“We leverage all the experience that the workers accumulate, no matter how much, whether it’s a success or failure — we still learn from it,” Wijmans explained.
What this means is that there are no wasted cycles where some workers are waiting for others to finish. Bringing more experience on the task at hand in on time means the next batch of slightly better workers goes out that much earlier, a self-reinforcing cycle that produces serious gains.
In the experiments they ran, the researchers found that the system, catchily named Decentralized Distributed Proximal Policy Optimization or DD-PPO, appeared to scale almost ideally, with performance increasing nearly linearly to more computing power dedicated to the task. That is to say, increasing the computing power 10x resulted in nearly 10x the results. On the other hand, standard algorithms led to very limited scaling, where 10x or 100x the computing power only results in a small boost to results because of how these sophisticated simulators hamstring themselves.
These efficient methods let the Facebook researchers produce agents that could solve a point to point navigation task in a virtual environment within their allotted time with 99.9% reliability. They even demonstrated robustness to mistakes, finding a way to quickly recognize they’d taken a wrong turn and go back the other way.
The researchers speculated that the agents had learned to “exploit the structural regularities,” a phrase that in some circumstances means the AI figured out how to cheat. But Wijmans clarified that it’s more likely that the environments they used have some real-world layout rules.
“These are real houses that we digitized, so they’re learning things about how western-style houses tend to be laid out,” he said. Just as you wouldn’t expect the kitchen to enter directly into a bedroom, the AI has learned to recognize other patterns and make other “assumptions.”
The next goal is to find a way to let these agents accomplish their task with fewer resources. Each agent had a virtual camera it navigated with that provided it ordinary and depth imagery, but also an infallible coordinate system to tell where it traveled and a compass that always pointed toward the goal. If only it were always so easy! But until this experiment, even with those resources the success rate was considerably lower even with far more training time.
Habitat itself is also getting a fresh coat of paint with some interactivity and customizability.

Habitat as seen through a variety of virtualized vision systems.
“Before these improvements, Habitat was a static universe,” explained Wijmans. “The agent can move and bump into walls, but it can’t open a drawer or knock over a table. We built it this way because we wanted fast, large-scale simulation — but if you want to solve tasks like ‘go pick up my laptop from my desk,’ you’d better be able to actually pick up that laptop.”
Therefore, now Habitat lets users add objects to rooms, apply forces to those objects, check for collisions and so on. After all, there’s more to real life than disembodied gliding around a frictionless 3D construct.
The improvements should make Habitat a more robust platform for experimentation, and will also make it possible for agents trained in it to directly transfer their learning to the real world — something the team has already begun work on and will publish a paper on soon.


